Untuk analisa data dengan tujuan uji beda, salah satu alat uji statistiknya adalah uji t. Uji t dalam olah statistik terdiri dari 3 variasi. Untuk detilnya bisa dilihat disini.
Salah satu variasi uji t adalah uji t sampel independen (independent-sample t test). Pada uji ini, sering saya jumpai banyak kawan mahasiswa yang bingung terkait interpretasinya. Hal ini karena di uji t sampel independen ada 2 alat uji yang ditampilkan (berdasarkan hasil uji dari aplikasi SPSS), yaitu:
- Levene’s test
- 2 baris uji t sampel independen (disinilah bingungnya, pilih yang mana, kenapa, dst…)
Baiklah, melalui tutorial singkat ini, semoga bisa membantu. Mari kita mulai….
Misalkan saya punya 2 variabel, yaitu:
- nilai, tipe data interval
- kelompok, tipe data nominal
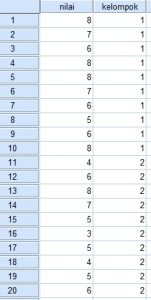
total kasus adalah 20 kasus, sehingga masing-masing kelompok ada 10 kasus.
Tujuannya adalah: melihat apakah ada perbedaan rata-rata nilai ujian antara kelompok 1 dengan kelompok 2.
Null Hypothesis, Ho: “Tidak ada perbedaan rata-rata nilai antara kelompok 1 dan kelompok 2“.
Karena kedua kelompok berbeda satu sama lain, maka kita gunakan uji t sampel independen. Berikut langkah-langkahnya di SPSS:

dari menu utama SPSS, pilih Analize, pilih Compare Means, pilih Independent-Samples T Test
tampil:
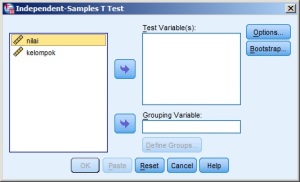
lakukan langkah berikut:
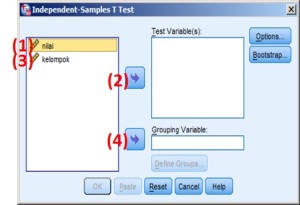
- klik var: nilai
- klik tombol (->) disamping text “Test Variable(s):“
- klik var: kelompok
- klik tombol (->) disamping text “Grouping Variable:“
hasilnya:
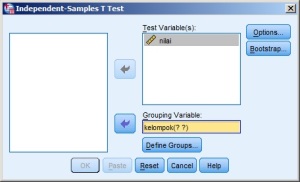
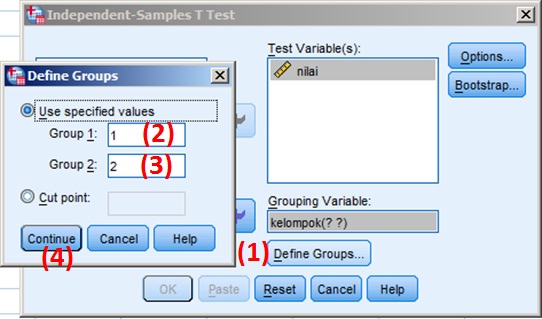
seperti yang terlihat digambar diatas, di text “Grouping Variable:” terlihat kelompok(? ?), artinya perlu langkah berikutnya yaitu menentukan nilai untuk melambangkan kelompok yang ada di data (dalam hal ini 1 untuk kelompok 1 dan 2 untuk kelompok 2).
Berikut langkahnya:
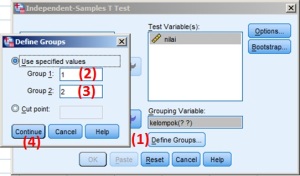
- klik Define Groups…
- ketik 1 di text Group 1: (karena 1 untuk kelompok 1, sesuai di data)
- ketik 2 di text Group 1: (karena 2 untuk kelompok 2, sesuai di data)
- klik Continue
hasilnya:
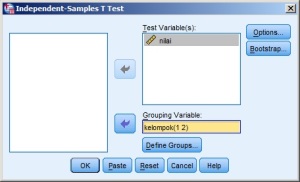
Sebagai langkah terakhir adalah klik tombol OK (samping tombol Paste).
Berikut hasil/output SPSS-nya:

Di output uji t, ada 2 baris hasil uji t dengan masing-masing memiliki nilai p-value (sig, (2-tailed)) yang berbeda yaitu 0.014 dan 0.015. Nah, disinilah yang membingungkan, pilih yang mana.
Perlu diperhatikan pada kolom kiri ada tulisan Equal variances assumed dan Equal variances not assumed. Artinya, baris pertama dipilih jika varians antara kelompok 1 dan 2 itu adalah identik (equal) dan pilih baris kedua jika varians antara kelompok 1 dan 2 itu tidak identik (not equal). Terus, dari mana nentuinnya?
Nah, di uji t sampel independen memberikan kita hasil uji Levene’s test yang bertujuan untuk menentukan kesamaan varians diantara kedua kelompok. Alat uji inilah yang digunakan untuk menentukan baris mana yang dipilih.
Uji Levene (Levene’s test) adalah sejatinya uji beda.
Berikut Ho untuk uji Levene (Levene’s test): “Tidak ada perbedaan varians antara kelompok 1 dan 2“.
Karena p-value = 0.460 (>0.05) maka Ho GAGAL di-TOLAK! Sehingga kesimpulannya adalah “Tidak Ada perbedaan varians antara kelompok 1 dan 2“. Karenanya maka uji t yang dipilih adalah baris 1 yaitu di baris Equal variance assumed (varians nya dianggap sama/identik/equal).
Sehingga p-value uji t yang dipilih adalah yang 0.014.
Berikut Ho untuk uji t-nya: “Tidak ada perbedaan rata-rata nilai antara kelompok 1 dan 2”
Karena p-value = 0.014 (< 0.05), maka Ho di-TOLAK!
Kesimpulannya adalah “Ada perbedaan rata-rata nilai antara kelmpok 1 dan 2”
Terus siapa yang lebih baik nilainya? Untuk menjawab ini lihat data pada kolom Mean Difference. Ternayta nilainya = 1.600.
Artinya nilai kelompok 1 > nilai kelompok 2. Kok bisa, ya karena hasil pengurangan nilai kelompok 1 dengan kelompok 2 adalah positif (1.600) sehingga mengindikasikan bahwa nilai kelompok 1 > nilai kelompok 2.
Demikian, semoga membantu…